 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForget, Then Recall: Learnable Compression and Selective Unfolding via Gist Sparse Attention
Apr 22, 2026Scaling large language models to long contexts is challenging due to the quadratic computational cost of full attention. Mitigation approaches include KV-cache selection or compression techniques. We instead provide an effective and end-to-end learnable bridge between the two without requiring architecture modification. In particular, our key insight is that interleaved gist compression tokens -- which provide a learnable summary of sets of raw tokens -- can serve as routing signals for sparse attention. Building on this, we introduce selective unfolding via GSA, which first compresses the context into gist tokens, then selects the most relevant gists, and subsequently restores the corresponding raw chunks for detailed attention. This yields a simple coarse-to-fine mechanism that combines compact global representations with targeted access to fine-grained evidence. We further incorporate this process directly into training in an end-to-end fashion, avoiding the need for external retrieval modules. In addition, we extend the framework hierarchically via recursive gist-of-gist construction, enabling multi-resolution context access with logarithmic per-step decoding complexity. Empirical results on LongBench and RAG benchmarks demonstrate that our method consistently outperforms other compression baselines as well as inference-time sparse attention methods across compression ratios from $8\times$ to $32\times$. The code is available at: https://github.com/yuzhenmao/gist-sparse-attention/
Neural Garbage Collection: Learning to Forget while Learning to Reason
Apr 20, 2026Chain-of-thought reasoning has driven striking advances in language model capability, yet every reasoning step grows the KV cache, creating a bottleneck to scaling this paradigm further. Current approaches manage these constraints on the model's behalf using hand-designed criteria. A more scalable approach would let end-to-end learning subsume this design choice entirely, following a broader pattern in deep learning. After all, if a model can learn to reason, why can't it learn to forget? We introduce Neural Garbage Collection (NGC), in which a language model learns to forget while learning to reason, trained end-to-end from outcome-based task reward alone. As the model reasons, it periodically pauses, decides which KV cache entries to evict, and continues to reason conditioned on the remaining cache. By treating tokens in a chain-of-thought and cache-eviction decisions as discrete actions sampled from the language model, we can use reinforcement learning to jointly optimize how the model reasons and how it manages its own memory: what the model evicts shapes what it remembers, what it remembers shapes its reasoning, and the correctness of that reasoning determines its reward. Crucially, the model learns this behavior entirely from a single learning signal - the outcome-based task reward - without supervised fine-tuning or proxy objectives. On Countdown, AMC, and AIME tasks, NGC maintains strong accuracy relative to the full-cache upper bound at 2-3x peak KV cache size compression and substantially outperforms eviction baselines. Our results are a first step towards a broader vision where end-to-end optimization drives both capability and efficiency in language models.
GIANTS: Generative Insight Anticipation from Scientific Literature
Apr 10, 2026Scientific breakthroughs often emerge from synthesizing prior ideas into novel contributions. While language models (LMs) show promise in scientific discovery, their ability to perform this targeted, literature-grounded synthesis remains underexplored. We introduce insight anticipation, a generation task in which a model predicts a downstream paper's core insight from its foundational parent papers. To evaluate this capability, we develop GiantsBench, a benchmark of 17k examples across eight scientific domains, where each example consists of a set of parent papers paired with the core insight of a downstream paper. We evaluate models using an LM judge that scores similarity between generated and ground-truth insights, and show that these similarity scores correlate with expert human ratings. Finally, we present GIANTS-4B, an LM trained via reinforcement learning (RL) to optimize insight anticipation using these similarity scores as a proxy reward. Despite its smaller open-source architecture, GIANTS-4B outperforms proprietary baselines and generalizes to unseen domains, achieving a 34% relative improvement in similarity score over gemini-3-pro. Human evaluations further show that GIANTS-4B produces insights that are more conceptually clear than those of the base model. In addition, SciJudge-30B, a third-party model trained to compare research abstracts by likely citation impact, predicts that insights generated by GIANTS-4B are more likely to lead to higher citations, preferring them over the base model in 68% of pairwise comparisons. We release our code, benchmark, and model to support future research in automated scientific discovery.
BoxingGym: Benchmarking Progress in Automated Experimental Design and Model Discovery
Jan 02, 2025



Understanding the world and explaining it with scientific theories is a central aspiration of artificial intelligence research. Proposing theories, designing experiments to test them, and then revising them based on data are fundamental to scientific discovery. Despite the significant promise of LLM-based scientific agents, no benchmarks systematically test LLM's ability to propose scientific models, collect experimental data, and revise them in light of new data. We introduce BoxingGym, a benchmark with 10 environments for systematically evaluating both experimental design (e.g. collecting data to test a scientific theory) and model discovery (e.g. proposing and revising scientific theories). To enable tractable and quantitative evaluation, we implement each environment as a generative probabilistic model with which a scientific agent can run interactive experiments. These probabilistic models are drawn from various real-world scientific domains ranging from psychology to ecology. To quantitatively evaluate a scientific agent's ability to collect informative experimental data, we compute the expected information gain (EIG), an information-theoretic quantity which measures how much an experiment reduces uncertainty about the parameters of a generative model. A good scientific theory is a concise and predictive explanation. Therefore, to quantitatively evaluate model discovery, we ask a scientific agent to explain their model and then assess whether this explanation enables another scientific agent to make reliable predictions about this environment. In addition to this explanation-based evaluation, we compute standard model evaluation metrics such as prediction errors. We find that current LLMs, such as GPT-4o, struggle with both experimental design and model discovery. We find that augmenting the LLM-based agent with an explicit statistical model does not reliably improve these results.
CriticAL: Critic Automation with Language Models
Nov 10, 2024Understanding the world through models is a fundamental goal of scientific research. While large language model (LLM) based approaches show promise in automating scientific discovery, they often overlook the importance of criticizing scientific models. Criticizing models deepens scientific understanding and drives the development of more accurate models. Automating model criticism is difficult because it traditionally requires a human expert to define how to compare a model with data and evaluate if the discrepancies are significant--both rely heavily on understanding the modeling assumptions and domain. Although LLM-based critic approaches are appealing, they introduce new challenges: LLMs might hallucinate the critiques themselves. Motivated by this, we introduce CriticAL (Critic Automation with Language Models). CriticAL uses LLMs to generate summary statistics that capture discrepancies between model predictions and data, and applies hypothesis tests to evaluate their significance. We can view CriticAL as a verifier that validates models and their critiques by embedding them in a hypothesis testing framework. In experiments, we evaluate CriticAL across key quantitative and qualitative dimensions. In settings where we synthesize discrepancies between models and datasets, CriticAL reliably generates correct critiques without hallucinating incorrect ones. We show that both human and LLM judges consistently prefer CriticAL's critiques over alternative approaches in terms of transparency and actionability. Finally, we show that CriticAL's critiques enable an LLM scientist to improve upon human-designed models on real-world datasets.
What Should Embeddings Embed? Autoregressive Models Represent Latent Generating Distributions
Jun 06, 2024



Autoregressive language models have demonstrated a remarkable ability to extract latent structure from text. The embeddings from large language models have been shown to capture aspects of the syntax and semantics of language. But what {\em should} embeddings represent? We connect the autoregressive prediction objective to the idea of constructing predictive sufficient statistics to summarize the information contained in a sequence of observations, and use this connection to identify three settings where the optimal content of embeddings can be identified: independent identically distributed data, where the embedding should capture the sufficient statistics of the data; latent state models, where the embedding should encode the posterior distribution over states given the data; and discrete hypothesis spaces, where the embedding should reflect the posterior distribution over hypotheses given the data. We then conduct empirical probing studies to show that transformers encode these three kinds of latent generating distributions, and that they perform well in out-of-distribution cases and without token memorization in these settings.
Automated Statistical Model Discovery with Language Models
Feb 27, 2024



Statistical model discovery involves a challenging search over a vast space of models subject to domain-specific modeling constraints. Efficiently searching over this space requires human expertise in modeling and the problem domain. Motivated by the domain knowledge and programming capabilities of large language models (LMs), we introduce a method for language model driven automated statistical model discovery. We cast our automated procedure within the framework of Box's Loop: the LM iterates between proposing statistical models represented as probabilistic programs, acting as a modeler, and critiquing those models, acting as a domain expert. By leveraging LMs, we do not have to define a domain-specific language of models or design a handcrafted search procedure, key restrictions of previous systems. We evaluate our method in three common settings in probabilistic modeling: searching within a restricted space of models, searching over an open-ended space, and improving classic models under natural language constraints (e.g., this model should be interpretable to an ecologist). Our method matches the performance of previous systems, identifies models on par with human expert designed models, and extends classic models in interpretable ways. Our results highlight the promise of LM driven model discovery.
Gaussian process surrogate models for neural networks
Aug 11, 2022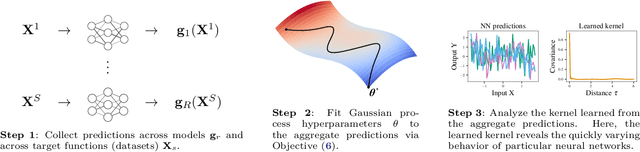
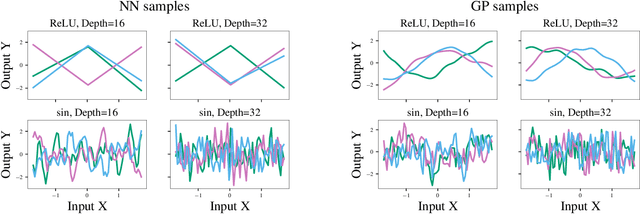
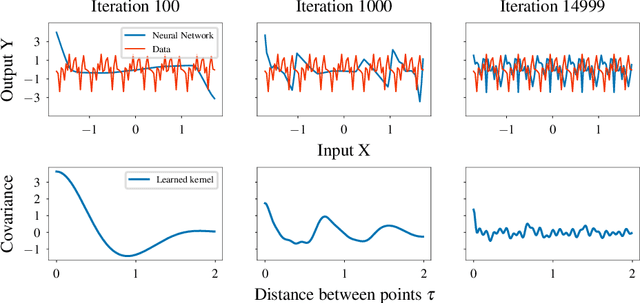
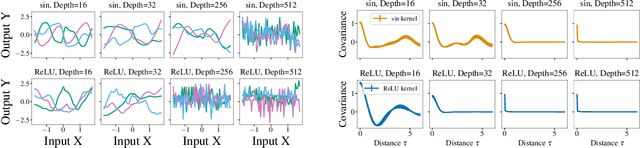
The lack of insight into deep learning systems hinders their systematic design. In science and engineering, modeling is a methodology used to understand complex systems whose internal processes are opaque. Modeling replaces a complex system with a simpler surrogate that is more amenable to interpretation. Drawing inspiration from this, we construct a class of surrogate models for neural networks using Gaussian processes. Rather than deriving the kernels for certain limiting cases of neural networks, we learn the kernels of the Gaussian process empirically from the naturalistic behavior of neural networks. We first evaluate our approach with two case studies inspired by previous theoretical studies of neural network behavior in which we capture neural network preferences for learning low frequencies and identify pathological behavior in deep neural networks. In two further practical case studies, we use the learned kernel to predict the generalization properties of neural networks.